Mon premier tool-assisted speedrun (TAS) : Astérix & Obélix (Game Boy Color)
Après un peu plus de six mois de travail de longue haleine, j’ai publié mon premier tool-assisted speedrun ! Le projet a été un exercice de recherche, d’optimisation et de programmation que j'ai trouvé très enrichissant et qui m’a apporté son lot de surprises tout au long du chemin.
Le tool-assisted speedrun, ou TAS, est l’art de trouver la façon la plus rapide de terminer un jeu vidéo en supposant que le joueur soit parfait et ne fasse aucune erreur. Ma curiosité et ma fascination ont été éveillées par les vidéos de RealMyop et Coeurdevandale aux alentours de 2012, puis au fil du temps, en regardant d’autres TAS, publiés sur TASVideos.org ou présentés au cours d’événements comme Games Done Quick, j’ai eu de plus en plus envie d’en faire un moi-même. Jusqu’à décider de me lancer en août dernier.
Dans ce billet, je vous expliquerai ce que le speedrun et le tool-assisted speedrun qui s’y apparente, puis je montrerai un peu l’envers du décor et mon propre vécu pour, je l’espère, inspirer d’autres personnes à s’y mettre.
Vous disiez « tool-assisted speedrun » ?
Pour comprendre ce qu’est le tool-assisted speedrun, il faut lire le terme de droite à gauche.
Commençons par le mot « speedrun ». Faire un speedrun, c’est prendre un jeu vidéo de son choix et essayer d’y jouer du début jusqu’à la fin le plus vite possible. C’est une course contre la montre qui se fait en temps réel et toutes les astuces sont permises : tous les raccourcis sont bons à prendre et tous les bugs sont bons à exploiter. Mais toute erreur a le potentiel de contraindre le speedrunner à recommencer du début : l’exercice requiert donc beaucoup d’adresse de la part du speedrunner.
Le tool-assisted speedrun, en revanche, cherche à apporter une réponse à une question théorique : sans erreur et avec une précision parfaite, comment finirait-on le jeu le plus rapidement possible ? Pour cela, l’auteur d’un TAS se munit d’un émulateur et enregistre des séquences d’actions à la manette de la console. On peut ralentir l’action, voire revenir en arrière pour refaire un passage. On peut utiliser un débogueur et rechercher les variables intéressantes du jeu en RAM pour les visualiser. On peut aussi automatiser la recherche de solutions à l’aide de scripts fonctionnant dans l’émulateur. Et dans les cas les plus extrêmes, on exploite un bug dans le jeu qui mène à une exécution de code arbitraire : le TAS finit donc par reprogrammer le jeu et lui faire exécuter une instruction pour sauter jusqu’au générique de fin.
Concrètement, donc, le TAS se présente sous la forme d’un fichier qui décrit à quel moment appuyer sur tel bouton sur la manette, et rien d’autre. On peut télécharger le TAS de quelqu’un d’autre, puis le rejouer dans un émulateur si on a également l’image de la ROM du jeu.
Si vous voulez en savoir plus, je vous renvoie vers une conférence de RealMyop et Coeurdevandale à ce sujet, qui montre aussi quelques exemples.
Les TAS qui m’ont marqué
Je me permets une parenthèse sur des TAS qui m’ont particulièrement impressionné quand je les ai vus pour la première fois, car j’estime qu’ils ont été pour moi une source d’inspiration.
Le premier qui me vient en tête est un TAS de Monopoly sur NES, aussi commenté par RealMyop et Coeurdevandale : c’est le premier TAS qui m’a introduit au concept de manipulation de chance. Puisque les algorithmes de génération de nombres aléatoires sont en réalité déterministes et parfois influencés par les boutons de la manette, un TAS peut provoquer des événements aléatoires plus favorables que la moyenne. Un bon exemple où la manipulation de chance est visible est un passage de ce TAS de Pokémon Vert Feuille, particulièrement impressionnant quand on connaît le jeu.
En matière d’exécution de code arbitraire, beaucoup d’exemples me viennent en tête. Le premier TAS que j’ai vu exploiter cette technique est un TAS de Super Mario Land 2 sur Game Boy. Mais cette technique peut être utilisée pour beaucoup d’autres usages humoristiques, comme ce TAS montré à l’édition 2016 d’Awesome Games Done Quick ou celui-là, qui pousse le concept jusqu’à son paroxysme.
Il existe aussi des TAS qui s’interdisent d’exploiter des bugs dans le jeu, et qui restent dans le cadre de ce qu’avaient prévu les développeurs. De bons exemples de cela sont des TAS de Pokémon qui montrent deux, voire trois jeux simultanés qui se connectent de temps en temps avec le câble Game Link pour échanger des monstres et finir entièrement le jeu comme on l’aurait fait en vrai, mais dans un temps record : notamment Bleu et Rouge ou Cristal, Argent et Jaune.
Comment je m’y suis lancé
Choisir le jeu
Pour mon premier TAS, j’avais envie de le faire sur un jeu que je connaissais plutôt bien : Astérix & Obélix, sorti sur Game Boy Color en 1999. Comme beaucoup de jeux à licence édités par Infogrames à l’époque, ce n’étaient peut-être pas des chefs-d’œuvre et certains passages pouvaient être très difficiles pour les mauvaises raisons, mais ce n’était clairement pas le pire jeu dans sa catégorie. J’apprécie particulièrement sa bande originale, composée par Alberto José Gonzalez (dont je fais remarquer l’existence d’une très sympathique introduction à son œuvre).
Je n’ai pas trouvé de TAS publié pour ce jeu : ni sur TASVideos.org, ni sur YouTube. J’étais donc tout particulièrement motivé pour combler ce vide.
Les premiers pas
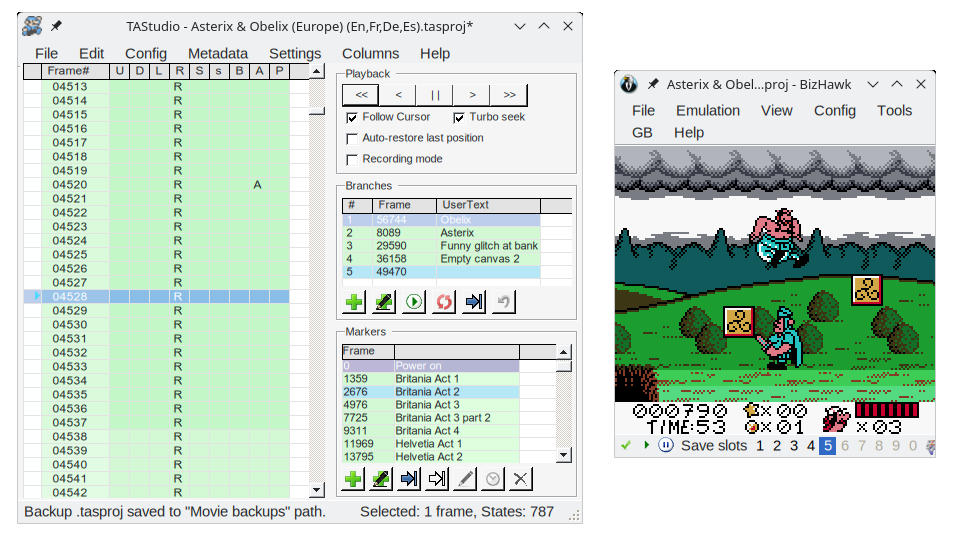
Le plus difficile est de commencer : il faut trouver la ROM (je vous laisse vous débrouiller), puis installer un émulateur approprié pour faire un TAS. J’ai utilisé BizHawk, dont il suffit de télécharger la dernière version et de suivre les instructions pour l’installer. Une fois ces étapes derrière soi, les choses sérieuses peuvent commencer.
Pour un premier TAS, le tutoriel vidéo (en anglais) par The8bitbeast est une très bonne ressource (la première vidéo de la série est très importante car elle montre comment configurer correctement l’émulateur), et je conseille de le regarder pendant qu’on pratique sur son propre jeu. Je l’ai découvert trop tardivement pour pouvoir le suivre, mais j’ai pu vérifier a posteriori que mon approche était bonne tout de même.
Recherche et mise en pratique
Puisque par définition, un TAS doit faire mieux qu’un speedrun classique, on peut aussi s’inspirer de ces derniers. Dans mon cas, un speedrun sur la version Game Boy du jeu montre que le TAS devrait dans tous les cas faire mieux que 19:39 minutes. Le visionnage d’autres speedruns de ce jeu montre que ceux-ci sont toujours faits en difficulté facile, qui raccourcit certains niveaux et fait apparaître moins d’ennemis par rapport à la difficulté normale.
Il est toujours très intéressant ensuite de regarder ce qui se passe dans la mémoire du jeu pendant qu’on joue. Concrètement, on utilise des outils comme le RAM Watch et le RAM Search pour trouver les variables intéressantes dans la mémoire du jeu. Quelques exemples : les coordonnées du personnage, sa vitesse, ses points de vie, ou ceux de ses ennemis.
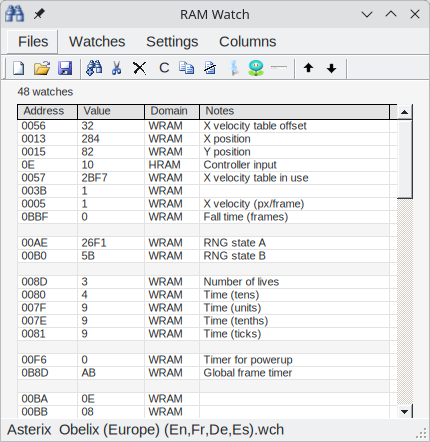
Fort de mon expérience de rétroingénierie du bus CAN de la Renault Clio III, j’ai pu trouver assez facilement les adresses mémoire que je souhaitais surveiller. Et je suis même allé plus loin en désassemblant le jeu : j’ai utilisé mgbdis avant de lire les listings de code assembleur quand cela me semblait indispensable. Là aussi, j’étais faux-débutant, car ce n’était pas la première fois que je décompilais du code (comme l’application Livephone ou, il y a fort longtemps, l’application Transilien pour Android) et le jeu d’instructions du CPU de la Game Boy est assez simple. Il n’y a pas forcément besoin de faire ce genre de choses pour réaliser un TAS, mais dans mon cas, cet effort s’est avéré indispensable pour optimiser un passage du jeu de fond en comble.
Les scripts
Et parfois, on développe ses propres outils. On peut lancer des scripts en Lua dans BizHawk pour accomplir diverses choses : afficher des informations supplémentaires, dessiner les hitboxes des ennemis par-dessus le jeu, ou (ré-)enregistrer des passages de manière semi-automatisée.
En chargeant par exemple le script ci-dessous dans l’émulateur, on peut visualiser la position (coordonnée x) de l’athlète romain :
while true do
local x = memory.read_u16_le(0x0502, "WRAM") +
memory.read_u8(0x0B7A, "WRAM") / 64
gui.text(8, 24, string.format("x = %7.6f", x))
emu.frameadvance()
end
Ce qui nous donne ensuite l’information superposée avec l’image :
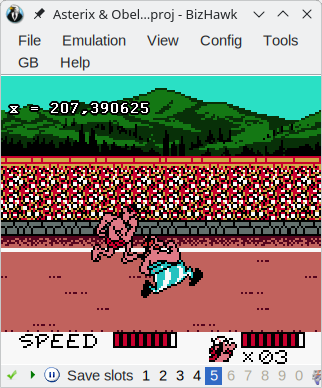
Dans mon cas, j’ai aussi eu besoin d’écrire un script pour un besoin bien spécifique : faire ce qu’on appelle de la manipulation de chance.
Les découvertes surprenantes
Quand on fait un TAS d’un jeu, et même quand on croit bien le connaître, il y a des astuces qu’on ne peut découvrir que grâce à la connaissance intime qu’on acquiert du moteur physique du jeu.
Par exemple, tapoter la croix directionnelle à une fréquence et un rythme bien précis pendant un saut permet au personnage de se déplacer plus vite que ce qu’avaient prévu les développeurs. Quand j’avais fait cette découverte, j’avais déjà couvert la moitié du jeu, et la mise en œuvre de cette technique m’a permis d’ôter trente secondes sur un total de huit minutes et demie.
La même technique marche aussi dans un niveau particulier, Helvétie Acte 4, niveau dans lequel il faut faire sauter les coffres-forts d’une banque pour délivrer le banquier enfermé dedans. Cela me permet de pousser les barils de poudre deux fois plus vite que l’intention des développeurs.
Il en émerge un bug graphique amusant : en temps normal, le baril de poudre qui ouvre le dernier coffre explose juste au moment où on a eu le temps de le pousser devant le bon coffre. Avec la technique de mouvement du TAS, il me reste du temps pour m’en éloigner. Mais si je suis suffisamment loin, le banquier est dessiné avec le mauvais jeu de couleurs : rouge, plutôt que gris ! Décidément, le souffle de l’explosion ne lui a pas fait beaucoup de bien.
Et il ne faut pas avoir peur non plus d’expérimenter et de voir ce qui se passe quand on presse des directions opposées simultanément : c’est ainsi que j’ai découvert qu’un appui simultané sur ↑ et ↓ à un instant très précis alors que je grimpe une échelle téléporte mon personnage tout en haut, pour un gain de temps non négligeable non plus.
Arbitrer entre rapidité et divertissement
Un bon TAS ne se contente pas seulement de finir le jeu rapidement : il doit aussi être un bon divertissement.
Par exemple, il pouvait m’arriver de prendre délibérément des coups pour aller plus vite ; mais si je parviens à trouver une stratégie alternative qui m’évite de prendre des dégâts mais qui termine un niveau avec exactement le même temps, je vais conserver la seconde stratégie car le résultat est plus agréable à regarder.
Parfois, il faut attendre. C’est plus amusant de se tortiller un peu n’importe comment durant les moments d’attente que de ne rien faire du tout. De même, dans les niveaux à défilement automatique (ou « autoscrollers »), l’occasion est parfaite pour jouer au casse-cou, comme dans ce TAS de Gradius, un jeu où les niveaux défilent automatiquement tout au long du jeu.
En revanche, il y a des situations où il vaut mieux faire quelque chose de moins optimal d’un point de vue du temps pour que le TAS ne soit pas trop ennuyeux. Par exemple, durant les Jeux olympiques, chaque épreuve est répétée trois fois. Au lieu de faire trois fois une performance parfaite, j’ai choisi de faire une fois la meilleure performance, puis une mauvaise, avant d’essayer de finir ex æquo. Le tout dans un esprit similaire à ce TAS de Track & Field sur NES. Ce passage est le seul endroit où j’ai délibérément choisi de perdre un petit peu de temps pour rendre le résultat plus divertissant.
La manipulation de chance
Alea jacta est
Comme déjà expliqué plus haut, les générateurs de nombres aléatoires (RNG) de jeux vidéo sont manipulables et il est parfois nécessaire ou intéressant d’obtenir un résultat qui aurait en temps normal été très rare, voire quasiment impossible. Il n’y a pas de technique universelle car chaque jeu est programmé différemment, mais une bonne ressource à ce sujet est le wiki de TASVideos.org.
La partie qui m’a donné de loin le plus de fil à retordre dans mon TAS était un niveau où Obélix affronte un athlète romain durant des Jeux olympiques : les performances de l’athlète adverse sont aléatoires et il fallait que les deux finissent la course pour que le jeu continue. Mon enjeu était donc de faire courir le Romain le plus vite possible en manipulant la RNG du jeu. Ces efforts ont été largement payants, car j’ai gagné 13 secondes en manipulant la chance tout au long des épreuves.
Dans mon cas, j’avais affaire à un générateur de nombres aléatoires qui était avancé une fois par trame et à chaque fois que le jeu a besoin d’un nombre aléatoire. L’aléa est dérivé du nombre de cycles CPU exécutés depuis le dernier rafraîchissement ; autrement dit, mon algorithme était dans la catégorie 3 de cette classification. Par conséquent, je pouvais parfois (mais pas systématiquement) influencer indirectement le résultat de la RNG en appuyant sur des boutons qui ne servent à rien.
Construire un arbre de possibilités
Puisque j’avais juste besoin de faire en sorte que le Romain coure plus vite que la normale, je n’ai qu’une seule variable à surveiller : la coordonnée x du personnage. Au départ, cette coordonnée vaut 69 et la ligne d’arrivée est à la coordonnée x = 2 720. En creusant, j’ai constaté que le jeu tirait une valeur aléatoire toutes les 4 trames (soit environ 15 fois par seconde) et que je pouvais obtenir une valeur différente en appuyant sur A, sur B ou sur A et B simultanément juste avant.
On peut donc visualiser l’ensemble des possibilités sous la forme d’un arbre, dont la racine est l’état de départ, les sommets sont les points de décision où la manette peut influencer l’aléa, et les arêtes sont les boutons appuyés. À chaque sommet correspond aussi un état du jeu qui est plus ou moins proche de sa condition de victoire.
Une partie de l’arbre des possibilités à 51 trames après le début de la course (au début, l’adversaire accélère d’une vitesse de base à une vitesse de croisière et les boutons ont une influence quasi nulle à ce stade). Les chemins colorés correspondent aux deux meilleures solutions ex æquo. Par exemple, en partant de l’état où l’adversaire est à la coordonnée x = 207,39, appuyer sur A ou sur A et B simultanément fait qu’au prochain point de décision 4 trames plus tard, l’adversaire se trouve à la coordonnée x = 217,79 ; mais n’appuyer sur aucun bouton l’amène à la coordonnée x = 218,26, ce qui est plus prometteur.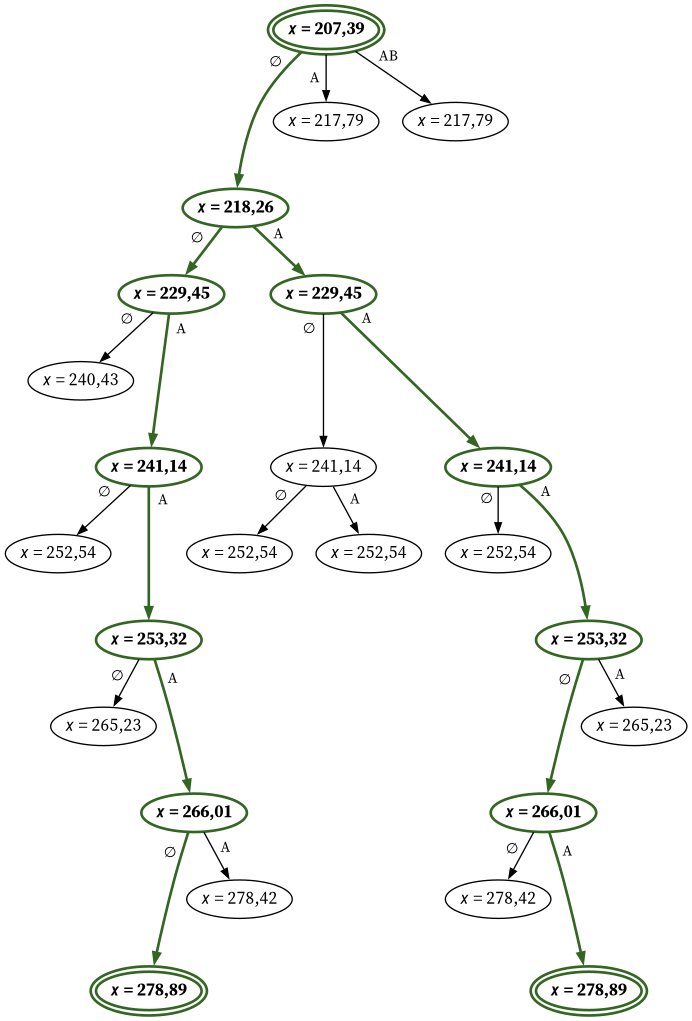
Dans le graphe de l’exemple ci-dessus, on peut observer l’influence de l’appui ou non sur des boutons à des moments décisifs sur la coordonnée x de l’adversaire. Ce graphe ne représente qu’une infime partie des possibilités : après hypothèses simplificatrices, l’arbre complet a une taille que j’estime à environ 2208 sommets.
Ce graphe est un instrument-clé pour nous aider à trouver la solution qui maximise la vitesse de l’athlète. On peut en effet la trouver en cherchant le plus chemin qui nous amène le plus rapidement jusqu’à l’arrivée. L’algorithme A*, un algorithme classique, peut donner des résultats optimaux dans les bonnes conditions. L’étape suivante est donc d’appliquer cet algorithme à mon arbre de possibilités, au moyen d’un script qui modifie mon TAS et examine les répercussions au fur et à mesure de la recherche.
Du A* à un A* modifié
Pour utiliser A*, il faut d’abord fournir ce qu’on appelle une fonction heuristique. Ici, on veut minimiser le temps de la course, donc la fonction heuristique doit, à tout moment, estimer le temps qu’il reste au Romain pour finir la course.
Diviser la distance restante à courir (2 720 − x) par sa vitesse maximale (206/64 pixels par trame) est une bonne heuristique, car elle ne surestime jamais le temps restant réel ; elle est donc dite admissible. C’est une bonne chose, car un A* donne un chemin toujours optimal si l’heuristique est admissible.
Le revers de la médaille, c’est qu’une heuristique admissible entraîne une exploration d’une très grande partie d’un arbre de possibilités qui n’aurait aucune chance de tenir dans la RAM de mon PC. J’ai donc dû opter pour une heuristique non admissible pour que le temps de calcul reste raisonnable. Pour cela, j’ai simplement multiplié l’heuristique par un poids constant W (paramétrable) strictement supérieur à 1. Ainsi, on trouve une solution beaucoup plus vite, mais on perd la garantie qu’elle soit optimale.
En pratique, ma pondération W était proche de 1 : j’utilisais généralement W = 206/203 ≈ 1,015 pour le 100 mètres et des valeurs de W comprises entre 1,032 et 1,040 pour le 100 mètres haies. Au moins, ainsi, je trouvais une solution en quelques dizaines d’heures. Par ailleurs, j’ai pu vérifier qu’une des solutions était tout de même optimale, en comparant le temps couru par le Romain par ce que j’avais calculé comme minimum théorique.
Je n’ai pas trouvé de terme en français pour cette adaptation de l’algorithme A*. En anglais, on dit « weighted A* search », donc je propose la traduction « recherche A* pondérée ».
En somme, le temps nécessaire pour développer et mettre au point le script de recherche, en plus du temps nécessaire pour comprendre le générateur de nombres aléatoires et comment les nombres tirés par cet algorithme sont utilisés dans le jeu, a fait passer la durée de réalisation de mon TAS de six semaines à six mois. Mais le jeu en valait largement la chandelle car j’ai la tranquillité d’esprit d’avoir trouvé un routage (quasi) optimal dans ce passage.
Conclusion
Après avoir passé au moins cinq à six semaines à relancer mon script sur les différentes épreuves des Jeux olympiques, j’ai décidé de considérer que j’avais suffisamment bien optimisé mon TAS pour tenter de la soumettre sur TASVideos.org.
Le temps d’attente entre la soumission et l’acceptation peut énormément varier suivant la disponibilité du jury, mais dans mon cas, je crois que j’ai eu de la chance car je n’ai attendu qu’une semaine avant que le TAS soit vérifié, puis admis.
L’étape suivante pourrait être d’essayer de vérifier le TAS sur console : autrement dit, rejouer le TAS sur le matériel authentique (bien qu’en substituant la manette) et vérifier qu’il fonctionne comme sur émulateur. L’émulation Game Boy a fait d’énormes progrès dans sa fidélité et la vérification sur console de jeux Game Boy se fait habituellement avec une GameCube munie d’un Game Boy Player et la cartouche originale, donc peut-être serait-ce quelque chose à tenter.
Vous savez à présent tout sur mon premier TAS. J’espère que cela vous ait permis de mieux comprendre ce qui se passe à l’écran durant le visionnage, et qui sait, peut-être cela aura-t-il inspiré certains d’entre vous à vous lancer à votre tour. Bon visionnage !